TrainScanner関連
TrainScannerは、通過していく列車の側面をビデオカメラで撮影して、その動画データからスリットスキャン写真を合成するための便利なツールです。

使い方について
ビデオカメラで撮影した動画データからスリットスキャン写真を合成する使い方については、TrainScannerのREADMEをご覧ください。
撮影した動画データの補助ツール(tsutil)
カメラで撮影した動画データには以下の課題があったため、tsutil - TrainScanner用の動画データを事前処理するためのツールを作りました。
- 列車の通過前・通過後の撮影時間の分だけ動画データのファイルサイズが大きくなり、ストレージを無駄に消費してしまう。
- パソコンに読み込ませると、カメラと比べて輝度や色合いが少し変わってしまうことがある。(私が使っているα7RIIIやα7SIIIではそうなる感じ)
- ホームでの手持ち撮影では、手振れによる画像のズレや水平・垂直出しに失敗して合成写真がガタガタになってしまうことがある。
tsutilは動画データから連続した画像データを作成し、色補正や手ブレ補正を行うことができます。さらに、Photoshopなどの画像処理ソフトを使って、画像データのノイズ低減・輝度・色補正などが可能になります。
また、以下のような動画データを生成する機能もあるので、SNSで写真を共有するのに便利です。

連続した画像データの読み込みについて
動画データの状態によっては、動画データを1フレームずつ画像ファイルに展開してPhotoshopなどで事前編集したい場合があります。(輝度や色調整、回転や台形補正、ブレ補正など)
動画から展開した画像ファイルは、そのままではTrainScannerに読み込ませることができませんので、連続した画像ファイルのカタログファイル(拡張子は.txtまたは.lst)を作成してTrainScannerに読み込ませるための改造を行っています。
なお、最新のTrainScanner(2025年6月現在)では、連続した画像ファイルの入ったフォルダ(ディレクトリ)をドラッグ&ドロップで開くことができるようになっています。
改造版TrainScannerのインストール方法です。ターミナルから以下のコマンドを実行してください。Pythonはuvでインストールできます。
uv pip install git+https://github.com/yamakox/TrainScanner.git@image-catalog-file-0.13.2
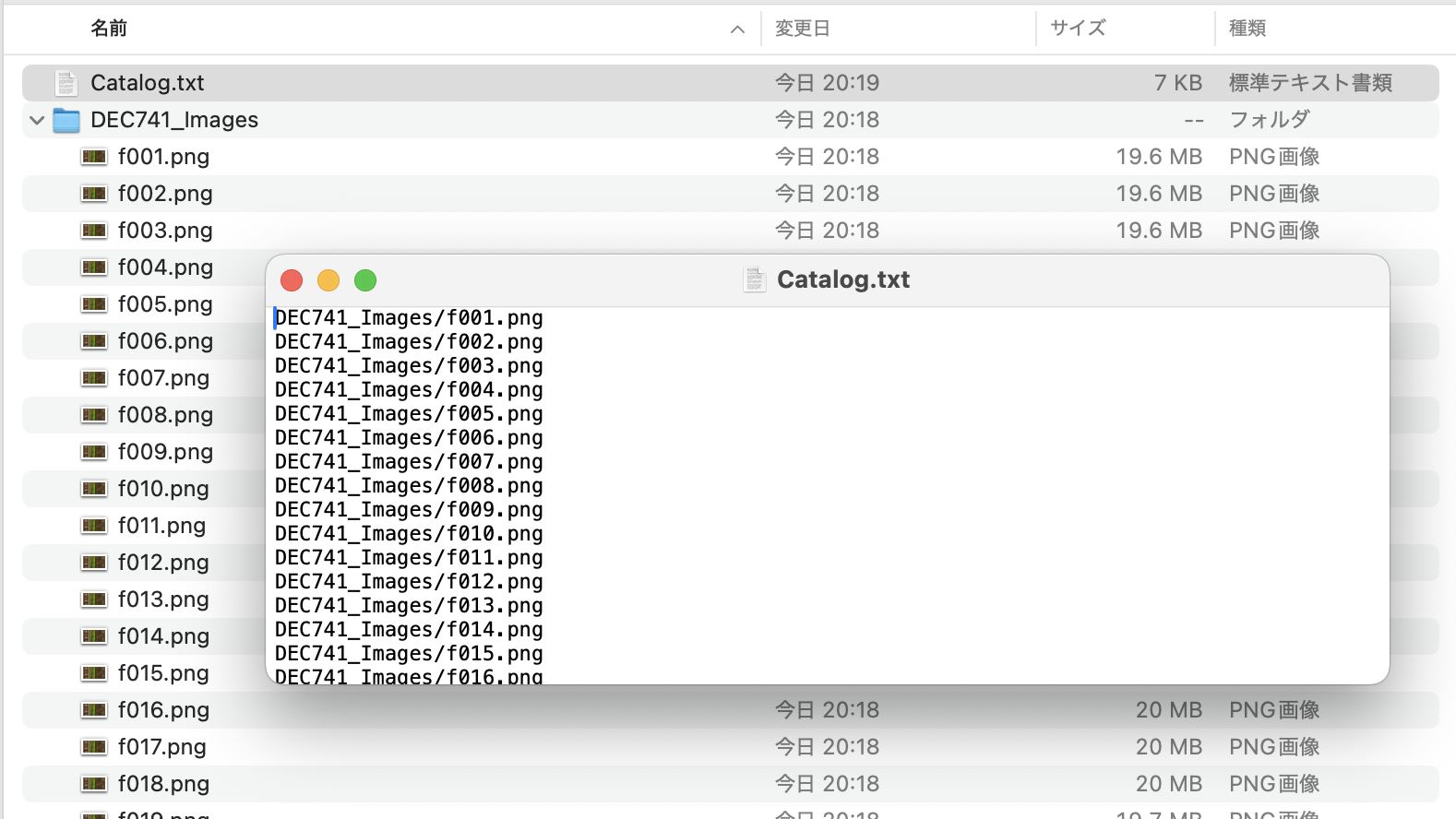
カタログファイルには、連続した画像ファイルのパス名(画像ファイルの格納場所)を1行ずつ順番に記しておきます。
.
├── Catalog.txt
└── 連続画像データ
├── f001.png
├── f002.png
├── f003.png
├── f004.png
:
例えば上記のように画像ファイルが格納されている場合、カタログファイルには以下のように画像ファイルのパス名を記しておきます。
連続画像データ/f001.png
連続画像データ/f002.png
連続画像データ/f003.png
連続画像データ/f004.png
:
ターミナルを使えば、以下のようにカタログファイルを作成することもできます。
ls -d 連続画像データ/*.png > Catalog.txt
120fpsのように隣り合うフレーム同士の移動距離が少ないデータの場合、フレームを間引いたカタログファイルを作るとよいです。
例えば、3行ごとにフレームを抽出するのであれば、以下のようなコマンドを使います。
awk "NR%3==0" Catalog.txt > ReducedCatalog.txt
TrainScanner 0.13.2ではcv2.matchTemplate(cv2.CCOEFF_NORMED)(参考)を使って検知枠内の画像が次のフレームのどの位置にいるかを探すため、
新幹線のように先頭部分が尖っていると検知枠内に写り込んでいる背景の部分が広くなり、先頭部分の移動距離がうまく検出できないことがあります。
その場合は、先頭部分だけのカタログファイルを作ってフレームの順序を逆転し、車両の中心側から先頭部分に向かって結合すると、うまくつながる場合があります。
awk '{a[i++]=$0} END {for (j=i-1; j>=0;) print a[j--]}' Catalog_1of2.txt > Catalog_1of2_reverse.txt
出来上がったカタログファイルは改造版TrainScannerの「ムービーを開く」画面から選択することができます。